Design spec for TextPicker
It’s hard to find examples of simple descriptions of simple applications online. Most seem to be meant for larger organisations. Here is the design specification for TextPicker, which the designers at draftss.com used when they designed the UI.
A Mac application for extracting text.
Background
Programmers, data scientists, prosumers and others often need to extract specific information from raw text, and may also wish to automate this or include this functionality in software they are making. Current methods are find/replace, regular expressions, writing parsers manually, or command line tools like grep, sed, awk, etc. These methods can be very complex, even for experienced programmers, and may often take longer to get working than just copying the desired information manually.
There are also commercial solutions like parseur.com (for parsing emails in raw text or html) and various web crawler services to extract data from web pages. These allow the user to just select the text they want extracted, and the software will then try to generalise a parser from that which it can use on the remaining or new text.
I have created a library which uses this latter approach. It takes as input a text, the ranges of the two first occurrences of what the user wants to extract (and optionally additional examples), and (optionally) ranges of text that should not be extracted. Hopefully very soon afterwards it outputs a parser which can be used to select the rest of the occurrences in the text.
Here is what the library needs to be able to generate a parser:
- The user must at least mark the 2 first occurrences.
- There must be at least one occurrence that the user has not marked.
- In other words, there must be at least 3 occurrences in total.
The user may have to be informed about these requirements in some way.
Prototype
I have created a prototype to demonstrate and test the functionality:
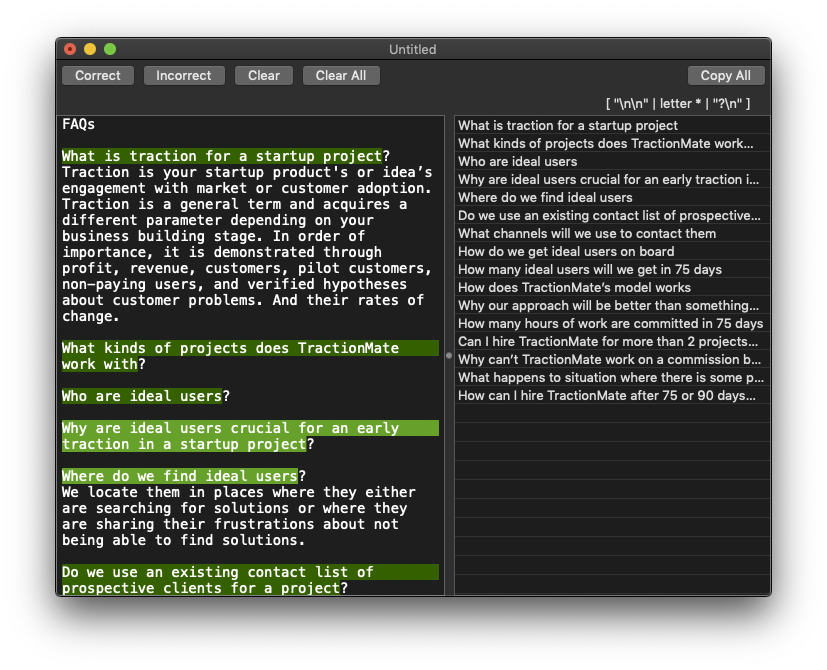
Note that the actual app doesn’t have to look anything like the prototype.
You can download it at [unavailable]. Note that it only supports the functionality described under “1 text, 1 type of data”, and while it can create some advanced parsers there is a lot of basic stuff it can’t handle yet. I’m working on it.
Here is a rough draft of the landing page, with an informative video.
Scenarios
Here are some use cases the application should support.
1 text, 1 type of data
The user has a text, and she wants to copy out all occurrences of one type of information, like all the questions from the screenshot above. It is her first time using the application. The application shows her where to paste the text, or how to open a text file, and also guides her to select at least the first 2 occurrences of what she’s looking for. When she does, the application automatically starts creating a parser. When it is done, it shows her the matches in the text itself, and allows her to mark any erroneous matches and also to select and mark text that was not matched but should be. As soon as she does any of this the application will immediately start creating a new parser and show the results. When the user is satisfied, she can easily copy all the matches (separated by newlines) to the clipboard.
I would prefer it if the application guides the user using placeholder text instead of a wizard/assistant/onboarding guide.
I plan to make this functionality available for free. The functionality described below will be available with a paid subscription.
1 text, multiple types of data
comments: true
date: 2009-03-29 18:55:54+00:00
layout: post
old_link: http://blog.nottoobadsoftware.com/iphone-development/a-uipickerview-with-labels/
slug: a-uipickerview-with-labels
title: A UIPickerView with labels
categories:
- iphone-development
tags:
- mySettings
- iPhone
---
Something something ...
Something something ...
...
From the text above the user wants to extract both the keys (“comments”, “date”, …, “tags”) and values (“true”, “2009-03-29 18:55:54+00:00”, …, “mySettings; iPhone”). Note that the 2 types of data have different counts, because “tags” has 2 values. She first selects “comments” and labels it as datatype “keys”. She then selects “date” and any other examples required for the parser to be created. Then she selects “true” and labels it as datatype “values”, and selects “2009-03-29 18:55:54+00:00” and so on. The 2 data types are marked with different colours to tell them apart.
The user can then copy out the results in formats like JSON, CSV, Excel or her own custom format, in a way that keeps the relation between each value and its key.
Multiple texts, 1 occurrence in each text
The user has several text files, with one occurrence of what she’s looking for in each file. She can’t train the parser on just the first file, because she needs to select the 2 first occurrences. The application allows her to load multiple text files at once, so she can mark the desired text in the first file, then in the second file, and then see what the application marks itself in the remaining files.
Parse matched text again
In the example above, there might be text below the “---“ divider that is automatically marked as “key” or “value”. To help the parser out and emphasise that only texts above the “---“ should be parsed the user can first select that text and mark it, and then do the same for the next text (she now needs multiple texts since she is marking just one region in each; see previous section). Then in the results view (which lists all the text that has been parsed) she can mark the text again, like in section “1 text, multiple types of data”. She can create parsers that parse the output of other parsers like this many times over.
Save/Reuse a parser
When a user has successfully created a parser, there are several ways she can export it to use it outside of the main application:
-
Stand-alone application
When opened, this helper application allows the user to either paste in text, or open one or more text files. It will then automatically parse all the text and output the results to the clipboard or to one or more text files, as chosen by the user. This helper application can also be used on other computers that do not have the main application installed. -
Command-line app
Similar to the helper application, this command-line application can either open files or parse text that is piped to it. -
macOS Service
This allows the user to select text in any application, right click on it, select “Services” and select the parser she created from the list. -
Automator action
The action will show up in the Automator application and can be used in Automator workflows/services etc. -
Code snippet
If the user is a programmer, she can get a code snippet she can use in any Swift source code. -
Web API
Eventually I might set up a web service users can upload their parsers to, and use them in online automation, like zapier.com.
User feedback
If the application is unable to create a parser, it might offer the user to send the text and what the user has marked to the developer, so I can take a look at it and see if this is something the application should be able to do. It will be important here to warn the user not to send anything confidential or that she does not have the rights to send to third parties.
Future features
Replacing text is something I would like to do in the future, but we can skip it for now as it complicates things too much.
Replace text
Instead of just outputting the parsed text the user can create parsers that edit the parsed text and puts it back in the original text.
The user wants to turn this:
Something something ...
<code class="bash">swift/utils/build-script --xctest --foundation -t
cd swift-corelibs-foundation
</code>
Something something ...
into this:
Something something ...
```bash
swift/utils/build-script --xctest --foundation -t
cd swift-corelibs-foundation
```
Something something ...
She can first mark the 3 indented lines, and the next example of similar text. In the results view she can then create a new parser for the leading 4 spaces of each line. Then in the next results view she can tell the application to replace all matches with nothing. The next results view will then show
<code class="bash">swift/utils/build-script --xctest --foundation -t
cd swift-corelibs-foundation
</code>
And here, like in “1 text, multiple types of data”, she can select 2 types of data; “language” = “bash” and “code” =
swift/utils/build-script --xctest --foundation -t
cd swift-corelibs-foundation
Then she can replace the original text with this template:
```<language>
<code>
```
To the designers
As you can see I have described what a user should be able to do with the application, but not what the user interface will be like. I have a few ideas on this but I’m not satisfied with them and I’m really looking forward to seeing what you can come up with.
As a general note, I would like the interface to be as simple as possible. I want it to be intuitive and preferably usable by non-programmers and users who don’t know what a parser is. I realise it is very difficult to come up with a good interface for a project like this, so please don’t hesitate to add comments here if something is unclear.
Deliverables
- Sketches of UI
- Descriptions of workflow
- App icon
- Any icons used in the app
- Groups of colours for marking different data types, easily distinguishable from each other.
- Everything needs to be for both normal and macOS Dark Mode
Comments